
SlashDB automatically generates a REST API from relational databases for reading and writing in convenient formats like XML, JSON and CSV. Additionally, using HTML it allows for simply browsing through data so users can discover available databases, tables, queries and API endpoints.
SlashDB is capable of providing a central access point to multiple databases, effectively forming an all-encompassing resource oriented architecture (ROA), serving as an API gateway to the data for users that need access.
How does SlashDB work?
SlashDB provides a web service shell for each of your database(s) by translating relational database structures into a logical library of uniform resource locators (URL). Conforming to REST methodology, every piece of data has its own unique identifying URL regardless of whether it is a simple scalar value or a nested structure of related records. For more information on data navigation and URL structures, please refer to the developer documentation here.
Data exposed in such a way can be used for processing in custom built applications such as enterprise information systems, or interactively in web and mobile apps, or for Business Intelligence solutions. Business analysts can utilize familiar tools like Microsoft Excel for self-service reporting on live data. Finally, hyperlinked data can be easily indexed in a search engine to enable natural language queries for databases. For other use case examples, please see the Solutions page.
How can SlashDB help?
SlashDB allows users to read and write data in two modes:
- Data Discovery – automatically reflects all objects in database as URL addressable resources
- SQL Pass-thru – configure any SQL statement and map it to a URL
In both modes data becomes addressable via simple URL.
Data Discovery

In this mode, all records automatically become HTTP resources, which can be read and updated. For example, an individual Customer’s record in the (example) Chinook database would be referenced like so: http://demo.slashdb.com/db/Chinook/Customer/CustomerId/1.html
Data becomes instantly available in several convenient data formats such as XML, JSON and comma-separated values text (CSV). The same record represented in JavaScript Object Notation (JSON) would be addressable as follows: http://demo.slashdb.com/db/Chinook/Customer/CustomerId/1.json
SlashDB effectively constructs a graph representation of all relational databases behind it. The system reflects the data model’s relationships, so links between related records are natural to follow. For example:
- Customer’s invoices can be referenced as: http://demo.slashdb.com/db/Chinook/Customer/CustomerId/1/Invoice.html
- The same filter, but from the Invoice table side: http://demo.slashdb.com/db/Chinook/Invoice/CustomerId/1.html
Drill-downs to vector slices and individual scalar values are also supported without sacrificing clarity of the URL link.
Customer’s name by itself, represented in XML can be reached using this URL: http://demo.slashdb.com/db/Chinook/Customer/CustomerId/1/FirstName.xml
Customers first name, last name and phone number: http://demo.slashdb.com/db/Chinook/Customer/FirstName,LastName,Phone.html?limit=10
In-lining related records within a document of a parent record is another powerful mechanism that simply works out of the box. In a single request you can get a Customer record with all his/her Invoice records.
http://demo.slashdb.com/db/Chinook/Customer/CustomerId/1.json?depth=1
There are plenty more powerful features in Data Discovery, but sometimes you may want or need to run an SQL query or a stored procedure. This is covered in the next section.
SQL Pass-thru Mode
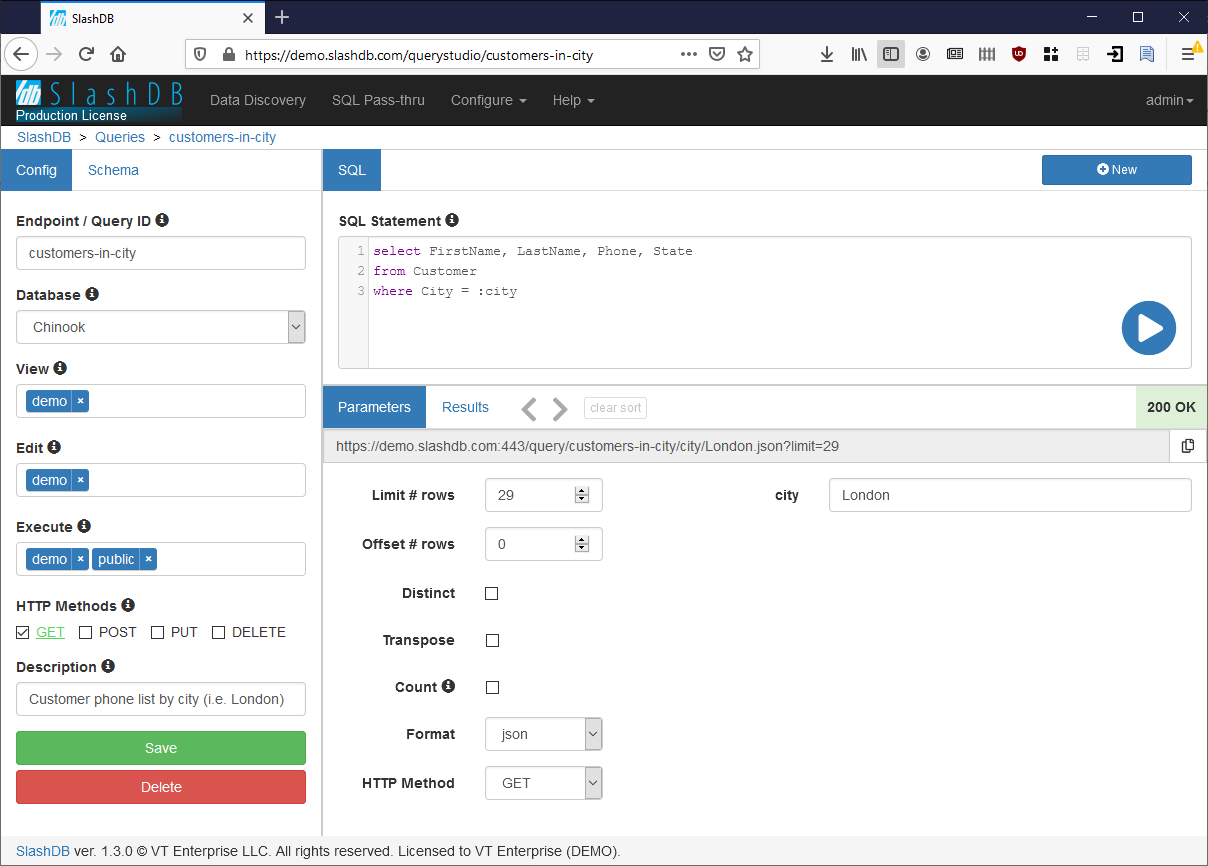
Using this mode, a SlashDB administrator or an application backend developer can define arbitrary SQL queries using the SlashDB configuration GUI. Once defined, those queries can be executed using a URL. For example this query returns customers from London:
http://demo.slashdb.com/query/customers-in-city/city/London.html
As before the results are available in all supported formats simply by changing the extension of the URL:
- http://demo.slashdb.com/query/customers-in-city/city/London.xml
- http://demo.slashdb.com/query/customers-in-city/city/London.json
- http://demo.slashdb.com/query/customers-in-city/city/London.csv
Queries can be fully parameterized. In fact to get customers from another city, simply substitute that part of the URL: http://demo.slashdb.com/query/customers-in-city/city/Chicago.html