
What is Lazy Loading?
Before we can describe what lazy loading in code means, we first have to look at how it’s different from what programmers are used to. You may not have heard the name for it before, but you’ve certainly used it before. Typical code uses an “eager” (rather than lazy) design pattern. We are all familiar with how this works: you tell the compiler or interpreter to allocate memory for a variable, and it does so, almost immediately. The variable happily sits in memory, able to be referenced until you deallocate it or the program garbage-collects it.
Now suppose that your code fetches this variable’s value from a really slow API service. In this case, an eager program design would be ineffective. The code’s execution halts until the API responds. In contrast, a lazy program design works like this: you write your code to call the API, but when run, the program, in effect, says to you, “yeah, yeah, I’ll get to it – but only if I have to.” When later in your script, you need this time-expensive value for a calculation or search, the lazy-style program will only then fetch the value and initialize the variable.
It seems like we’re only moving the problem from one place in the code to another: you still have to fetch the attribute anyway. This is why a lazy design pattern isn’t always friendly, but there are certain cases where this style of coding is helpful. When it comes to programming, examples are usually better than words. Let’s take a look at how you might implement lazy loading yourself.
Demo: Lazy Loading using Python and the SlashDB Chinook Database
For starters, let’s make ourselves a function to fetch data from the API. For this example, we’ll use SlashDB’s demo Chinook Database. Using the requests module from PyPI, our function will take a relative API URL, fetch that data, and return the JSON response.
import requests
BASE_URL = 'https://demo.slashdb.com/'
def retrieve_data(rel_url):
url = BASE_URL + rel_url
response = requests.get(url)
# Throw an exception on HTTP errors (404, 500, etc).
response.raise_for_status()
# Parse the response as JSON and return a Python dict.
return response.json()
We use a relative URL as the parameter because the API implements relationships in JSON using relative URLs, so this bit of code will save us some string work later.
APIResponse class
The API responses are dicts in our code, so we want our class to model the response to behave like a dictionary, except we’ll override the normal key-value lookup behavior to insert our lazy behavior. Inheriting from core Python core types such as list, str and dict can be messy and behave unexpectedly, because these types are implemented in C, rather than Python. So we need to try something else.
Thankfully the Python standard library comes to the rescue! We can create our API response class to inherit from the Mapping abstract base class from the collections.abc module. As far as the rest of our code can tell, APIResource is the same as dictionary in terms of functionality. If we forget to add any methods, our code would not run – that’s why inheriting from an abstract base class is useful. Another handy side effect of this inheritance is that our APIResponse becomes immutable, which makes sense for an object modeling a read-only API. Here’s our code:
from collections.abc import Mapping
import requests
# ----- snipped retrieve_data() ------
class APIResponse(Mapping):
def __init__(self, **kwargs):
if kwargs.get('response') is not None:
self.json_response = kwargs.get('response')
elif kwargs.get('url') is not None:
self.__href = kwargs.get('url')
self.json_response = None
else:
database = kwargs.get('database')
table = kwargs.get('table')
resource_id = kwargs.get('resource_id')
self.__href = f'/db/{database}/{table}/{table}Id/{resource_id}.json'
self.json_response = None
def __getitem__(self, key):
self.__load()
val = self.json_response[key]
if not (isScalar(val) or isinstance(val, APIResponse)):
# Check if the attribute is a relationship with other API data
# If val is a dictionary with only 1 key ('__href'),
# then more data is available for download
if '__href' in val:
val = APIResponse(url=val['__href'])
self.json_response[key] = val
return val
def __load(self):
if self.json_response is None:
self.json_response = retrieve_data(self.__href)
return None
__init__
This definition of __init__ allows our code to construct APIResource objects in three different ways. The first way, the constructor can take a dictionary of data to serve as the json_response, which could be useful in caching implementations because it avoids calling the API at all. The second and simplest method is by passing a URL. And finally, the constructor also takes keyword arguments for the desired database, table, ID of the relevant data, and builds the URL from those. For these last two methods, notice that json_reponse is set to None – we’ll give it a value later. This is the first hint of lazy loading.
__getitem__
By operator overloading __getitem__ we allow our APIResponse to act like a dictionary, but we can insert our lazy loading features here. The code is simple. When a value is requested (using response['Key']), __getitem__ first checks if this response has fetched its data from the API yet by using the __load function. This is the first aspect of lazy loading in our code – why fetch data until you know you need it? After calling the API, __getitem__ checks if the value requested is actually a relationship to another API object, and if it is, the function creates a new APIResponse instance to return. This is the other piece of code that makes our class lazy, all attributes that require a separate API call have laziness built in.
The sharper reader will notice our code calls a function that does not exists yet – isScalar. It’s a simple function; all it does is tell our code if the value requested is an int, float, bool, or str, the scalar types of JSON.
def isScalar(value):
return isinstance(value, (int, str, float, bool))
Odds and Ends
We can’t quite run this code yet. Before we can create APIResponse objects, our Mapping inheritance means we need to define all of the abstract methods inside that abstract base class. Specifically, we need to add __iter__ and __len__. While we’re at it, let’s make the code a little more developer friendly by adding a few helpful methods. We’ll add some class methods for easier instantiation, along with a few other Python “magic methods”, which only pass their behavior from self.json_response.
class APIResponse(Mapping):
# ----- snipped __init__, __getitem__ -----
@classmethod
def fromJSONResponse(cls, response):
"""Create an APIResponse object from existing data."""
return cls(response=response)
@classmethod
def fromURL(cls, url):
"""Create an APIResponse object from a relative URL."""
return cls(url=url)
@classmethod
def fromKeys(cls, database, table, resource_id):
"""Create an APIResponse object from a database, table, and id."""
return cls(database=database, table=table, resource_id=resource_id)
def __len__(self):
self.__load()
return len(self.json_response)
def __iter__(self):
self.__load()
return iter(self.json_response)
def __contains__(self, key):
self.__load()
return key in self.json_response
def __repr__(self):
if self.json_response is None:
return f'<unfetched APIResponse object>'
else:
return '<APIResponse ' + repr(self.json_response) + '>'
How Does Lazy Loading Work?
In order to understand exactly how lazy loading performs, we’ll use a debugger to really illustrate what’s going on and give you a clearer view. First, we create an APIResponse called resp from a URL.
resp = APIResponse.fromURL('/db/Chinook/Album/AlbumId/1.json')
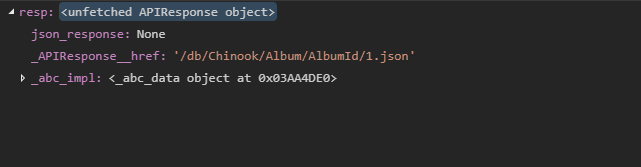
Now let’s look at the title for this album.
resp['Title']
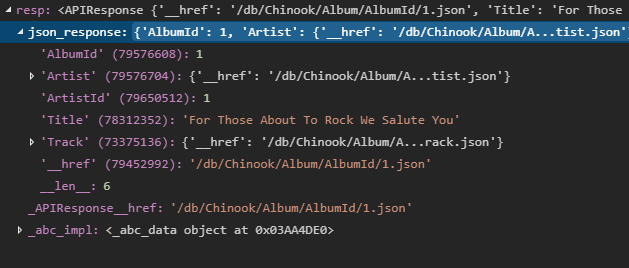
Look at all those new keys in json_response! Our code fetched the data from the API, but you’ll see on Artist and Track we have links to other data in the API. This is where lazy loading shines. Let’s try to look at one of those keys.
resp['Artist']
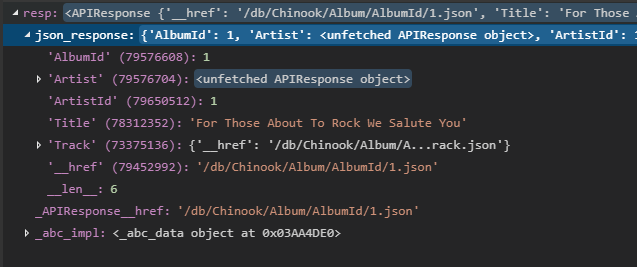
This program is really lazy! You asked for Artist so it gave you an APIResponse and it didn’t even bother to fill out any of its attributes. Laziness creates more laziness.
The Pudding – Testing Out Lazy Loading
To put lazy loading to the test, let’s use Python’s timeit module to compare our APIResponse class to an eager alternative. To make this class for comparison, I copied and pasted the code for APIResponse into another file and removed some of the “lazy” functionality. If we removed all lazy functionality, one API request would attempt to fetch the whole database, piece by piece, through the original requests’s relationships, through those relationships own relationships, through the relationships’ relationships’ relationships and so on. In this case, our eager class fetches its direct attributes, and no more. It will not fetch the attributes of its relationships.
Test #1
For our first test, we’ll have Python create an APIResponse object over and over again, and then access a single attribute. We’ll run the test 10 times and then 100 times. Here are the results, copied and pasted from my terminal.
$ python time_test.py # test 10 times Time for lazy: 2.734821861 Time for eager: 38.222376892 Lazy was about 14 times faster! $ python time_test.py # test 100 times Time for lazy: 27.830144855 Time for eager: 383.906078893 Lazy was about 14 times faster!
Test #2
For our other test, we’ll iterate through the first 10 albums (AlbumId’s 1-10), and check how many of those albums have more than 10 tracks. Obviously the exact details of this test aren’t important, what’s important is that we’re iterating through the responses and checking attributes.
$ python time_test.py # test 1 time Time for lazy: 4.964331371 Time for eager: 33.088113383 Lazy was about 7 times faster! $ python time_test.py # test 10 times Time for lazy: 50.144948269 Time for eager: 333.422545044 Lazy was about 7 times faster!
Obviously all tests were conducted on the same computer, internet connection, etc. Between tests, I changed the number of tries within the script. If you’re unsure if your code will be faster with lazy loading, try it out and do a time test yourself for your situation. These two samples are not indicative of every case ever.
When Should You Use Lazy Loading?
Lazy loading may appear very attractive, especially to new developers. It’s tempting to start adding it to all of your classes or attributes, just in case you don’t use all of your object’s attributes. The downside is that lazy loading overrides the normal indexing access, so your code becomes confusing quickly, and hard for other developers to read. Avoid the temptation to use lazy loading, unless you know that you need it. You should use lazy loading if you have no way to predict which attributes another developer/end-user will use and either an attribute, such as one with a numerical value, that takes a long time to calculate or an API used by your code has slow response times.
It’s worth noting, if another piece of code will certainly use an attribute that takes a long time to calculate, there is no need to apply lazy loading. It doesn’t matter whether you calculate a value now or later, it will slow down your program the same amount regardless of when the processor calculates it. Similarly, if the API your program uses has fast response times, lazy loading might not improve your code. Run a side by side test to see which is faster. When you’re making a decision, be sure to remember that readability and maintainability matter – a lot.
The very curious reader, can find all of the code I used for this tutorial/example here on my GitHub. Your constructive comments and improvements are welcome!